")
Tabla de contenidos
Le pedimos a tres IA que predijeran el Mundial 2026. Ninguna se puso de acuerdo.
Un experimento en directo de Hubler que demuestra, con un balón de por medio, por qué ningún modelo de inteligencia artificial es completamente objetivo.
Si hoy le preguntas a ChatGPT quién va a ganar el Mundial 2026, te dará una respuesta segura y convincente. Si le haces la misma pregunta a Claude, también. Y a Gemini, igual. El problema es que las tres respuestas serán distintas. Y si les cambias los datos que les das, volverán a cambiar de favorito sin pestañear.
En Hubler aplicamos inteligencia artificial al negocio de nuestros clientes, y hay una pregunta que aparece en casi todos los proyectos: ¿hasta qué punto me puedo fiar de lo que predice un modelo? Para responderla sin tecnicismos, montamos un experimento con la excusa perfecta: el Mundial 2026. El objetivo no era acertar el campeón. Era demostrar, de forma visible, que una predicción depende tanto del modelo que usas como de los datos que le pones delante.
Cómo montamos el experimento
Pusimos a competir cuatro motores sobre la misma pregunta: ¿qué probabilidad tiene cada selección de clasificarse, ganar su grupo y levantar el trofeo?
El primero es un simulador estadístico clásico — un motor de Monte Carlo — que recrea miles de veces el torneo completo, partido a partido, con las reglas de la FIFA. Los otros tres son los grandes modelos de lenguaje del momento: GPT-4.1, Claude Sonnet 4.5 y Gemini 2.5 Pro.
Cómo garantizamos la honestidad del experimento
Tomamos dos decisiones importantes para que los resultados fueran representativos de lo que obtiene cualquier usuario real.
Consultamos a las IA a través de su API estándar, sin ajustar parámetros, sin acceso a Internet y sin instrucciones adicionales. Solo un prompt con los datos y la petición de probabilidades. Es exactamente lo que obtendría cualquier persona que abriera la aplicación y preguntara.
Además, cada modelo opina una sola vez sobre cada escenario, y a partir de esa opinión simulamos el torneo miles de veces para convertir su valoración en probabilidades. Todas las predicciones se publican con fecha y hora, congeladas. No se reescriben después. Esto, que parece un detalle, es la base de cualquier ejercicio de forecasting serio.
Qué encontramos: los mismos datos, tres campeones distintos
Hallazgo 1: el modelo importa tanto como los datos
Empezamos por lo razonable. Le dimos a los cuatro motores un conjunto de datos basado en el histórico de cada selección: su ranking FIFA y su palmarés en mundiales. Datos de peso, los que usaría cualquiera para hacer una predicción fundamentada.
Con la misma información, cada motor eligió un favorito diferente:
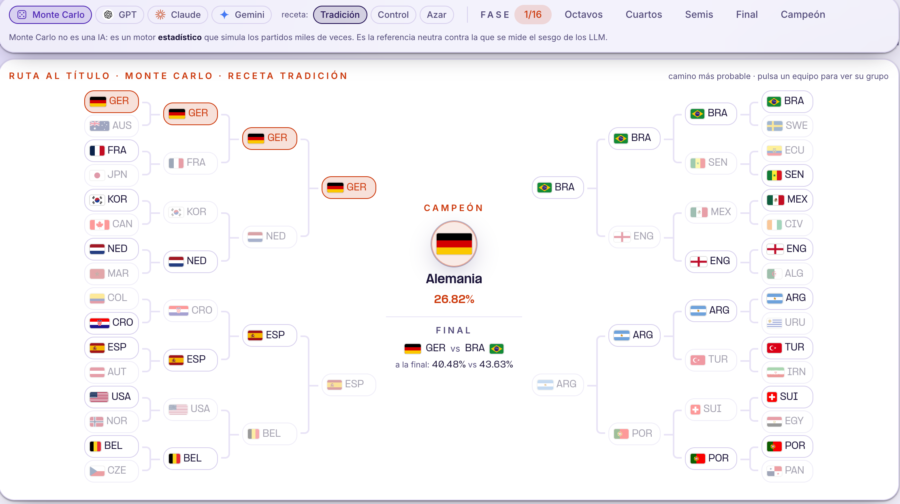
- Simulador estadístico: Alemania, con un 26,8% de probabilidad de ganar el torneo.
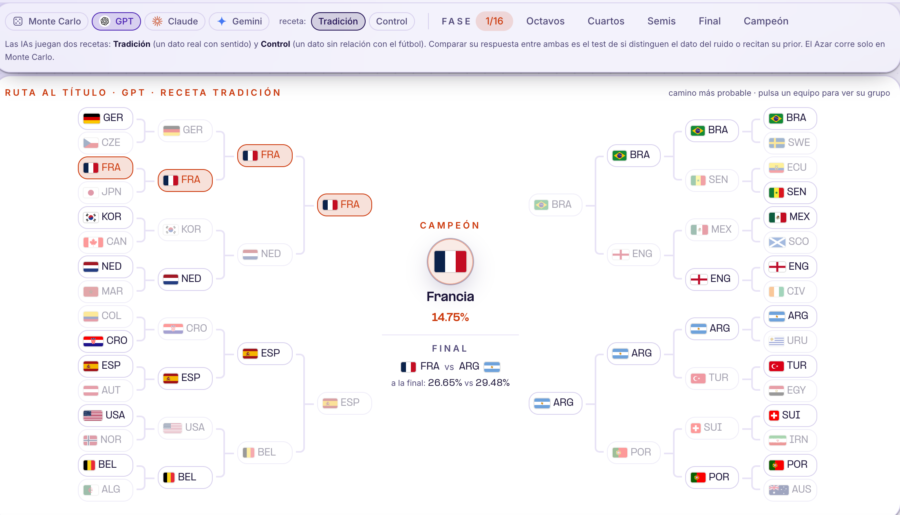
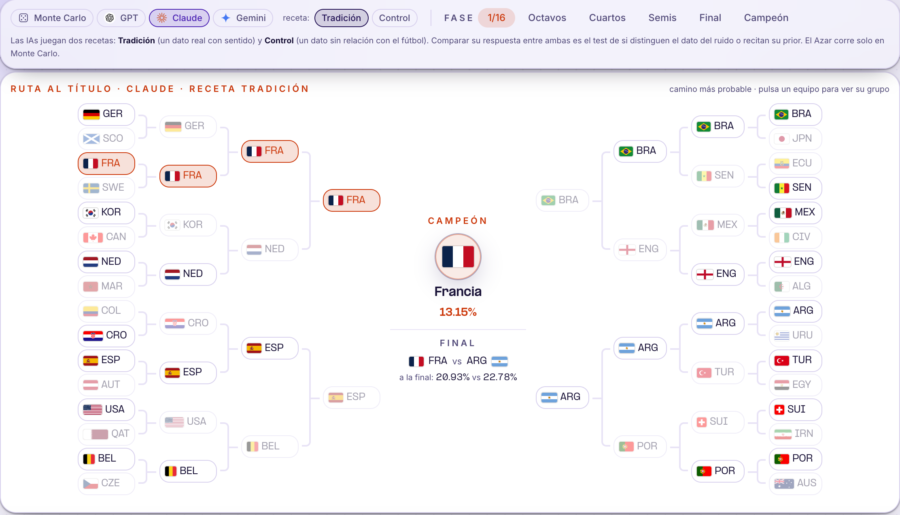
- ChatGPT y Claude: Francia, con un 14,75% y un 13,15% respectivamente.
- Gemini: Brasil, con un 24,7%.
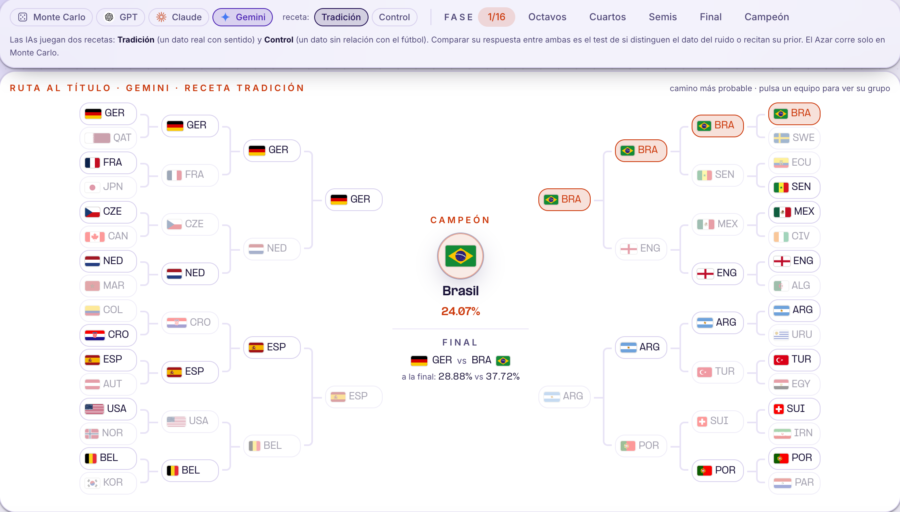
Cuatro motores, los mismos datos, un solo punto de coincidencia en lo más alto. La conclusión es directa: no existe «la predicción de la inteligencia artificial». Existe la predicción de GPT, la de Claude, la de Gemini y la del simulador. Solo con cambiar el modelo, cambia el favorito.
Hallazgo 2: un modelo no distingue entre un dato útil y uno irrelevante
Aquí es donde el experimento se vuelve más revelador. Repetimos la pregunta, pero sustituyendo los datos por otros igual de reales y completamente inservibles para predecir un resultado deportivo: la densidad de población del país y la edad media de la plantilla.
La pregunta era sencilla: ¿reconocería algún modelo que esos datos no sirven?
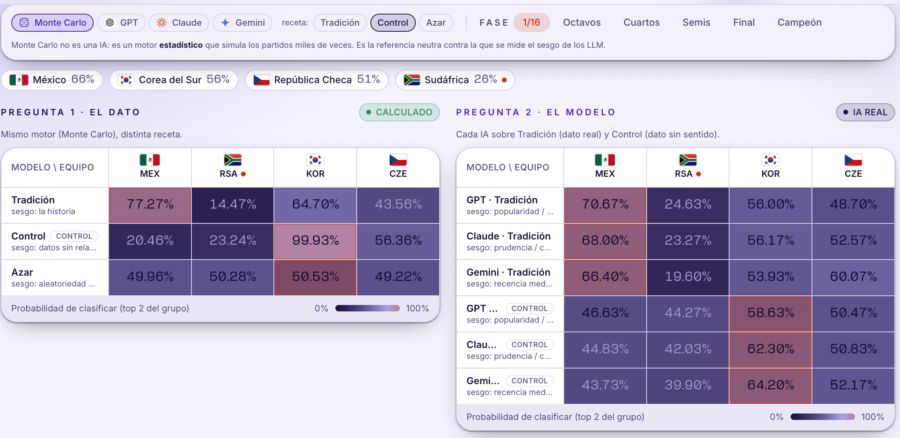
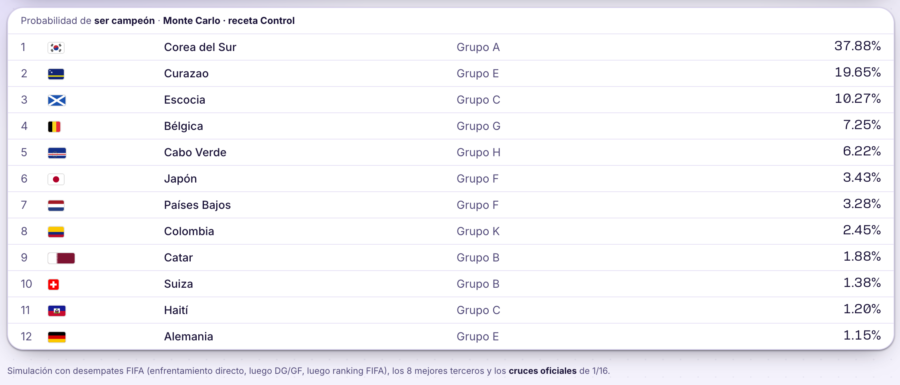
La respuesta fue no. Ninguno levantó la mano. El simulador estadístico (Monte Carlo), que se limita a ordenar por los números que recibe, seleccionó a Corea del Sur con un 37,9%, solo por tener una de las plantillas más veteranas. Gemini siguió ese mismo rastro y también puso a Corea del Sur en cabeza, con un 19,8%. ChatGPT y Claude se quedaron casi sin favorito claro — su mejor apuesta no llegó al 5% — pero, en lugar de advertir que la información era inservible, construyeron una predicción igualmente.
Ese es el matiz incómodo: un modelo no tiene sentido común. No distingue entre un dato valioso y uno absurdo a menos que se le enseñe explícitamente a hacerlo. La seguridad con la que responde no dice nada sobre la calidad de lo que le has dado.
Qué son los sesgos de la IA y por qué importan en el negocio
En este experimento conviven dos sesgos distintos, y los dos son relevantes fuera del fútbol.
Sesgo del modelo
Con datos idénticos, cada IA llega a una conclusión distinta porque arrastra los patrones aprendidos durante su entrenamiento. Cada modelo tiene sus propias tendencias, y esas tendencias se cuelan en la respuesta aunque no se lo pidas.
Sesgo del dato
La predicción solo ve lo que pones delante. Cambia el dato y cambia el resultado, incluso cuando el dato nuevo no tiene ningún valor real. El modelo no filtra por ti.
La conclusión no es que la inteligencia artificial sea poco fiable. Es que no es neutral. Una predicción es siempre el cruce de un modelo concreto y unos datos concretos. No es una verdad objetiva que sale de la máquina.
Qué tiene esto que ver con tu negocio
Cambia «quién gana el Mundial» por «cuántas unidades venderé el próximo trimestre», «qué cliente se va a dar de baja» o «qué pedido va a llegar tarde», y el experimento deja de ser un juego.
Las mismas dos preguntas que nos hicimos con el fútbol son las que hay que hacerse antes de tomar una decisión de negocio con un modelo:
- ¿Qué datos le estoy dando, y sé cuáles pesan de verdad y cuáles son ruido?
- ¿Qué modelo estoy usando, y entiendo hacia dónde tiende a inclinarse?
Una herramienta de IA que escupe un número con seguridad no es lo mismo que una predicción que entiendes y de la que te puedes fiar. El foco tiene que estar en la arquitectura de la solución: montar sistemas cuyas decisiones se pueden explicar, auditar y cuestionar. Cuando el sesgo deja de ser invisible, pasa a ser algo que controlas.
Accede al experimento
El experimento completo está disponible en mundial.hubler.es. Puedes ver, selección por selección y grupo por grupo, dónde coinciden los modelos y dónde divergen, y cómo cambia todo según los datos que reciben. Actualizamos las predicciones a lo largo del torneo y las comparamos con lo que va ocurriendo sobre el césped.
Y si después de verlo piensas en los modelos que ya usas para decidir en tu empresa, esa es exactamente la conversación que queremos tener contigo.

